Context
For a project I'm working on, we are using Ansible to deploy a small fleet of containers via Docker Compose to manage a pretty simple deployment flow. Nothing too fancy. And that was intentional. The whole point was to keep the deploy understandable, easy to debug, and not turn a small stack into an infrastructure project.
Still, we had a problem. The deploy had a downtime window of around 30 seconds, and for this kind of application that was not acceptable. Thirty seconds does not sound dramatic when you say it quickly, but if users are active and the app is part of a real workflow, it is enough to create friction and support noise. And after a while you stop thinking of it as a small issue. It just becomes the thing you know will happen every time you deploy.
The thing was that we were only using one replica for each container. That detail matters a lot more than it seems at the start, and it came back later in every version of the solution we tried.
At the start, the shape was more or less this:
services:
app:
build: .
healthcheck:
test: ["CMD", "curl", "-f", "http://localhost:3000/health"]
proxy:
image: reverse-proxy:stable
Which is fine until you realize that replacing that one app container means users feel every restart.
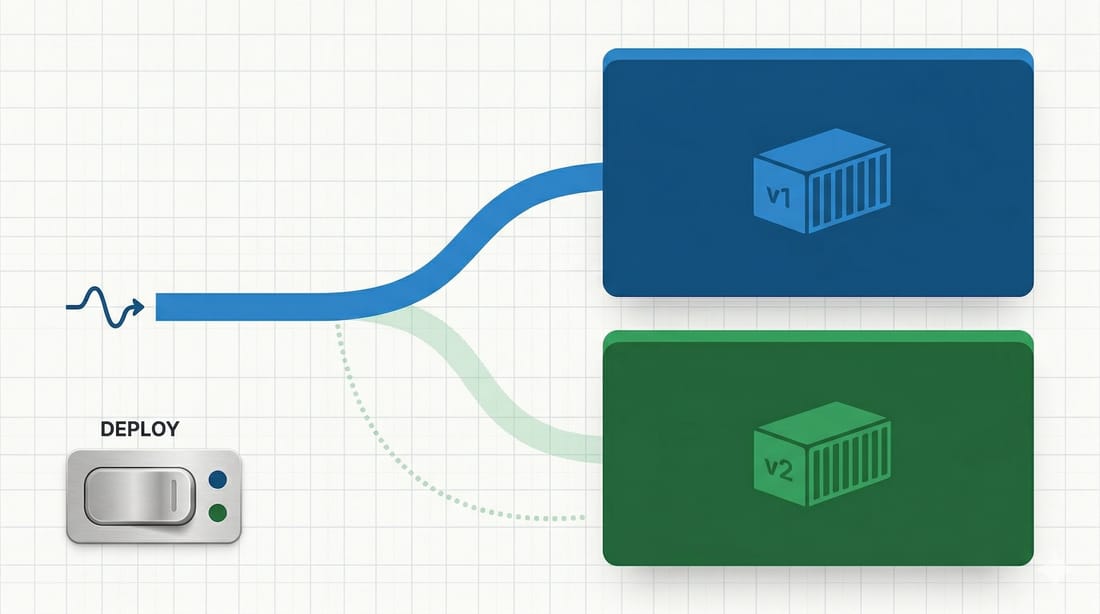
First try
So the first direction was obvious enough. We tried to add a green-blue deployment model while keeping the same Dockerfile and the same Docker Compose setup. The idea was simple: recreate one of the two app containers, check that everything is doing fine, wait for the health checks to pass, and then switch the proxy to point to the other application. On paper that is clean. One app stays live, the other gets rebuilt, then traffic moves.
And honestly, I still think that idea is fine in general.
The problem was the way it behaved in our setup. With only one replica behind each side, it felt clunky and not really stable. You can make it work, but every step suddenly matters too much. The timing matters. The proxy switch matters. The health check timing matters. The app warm-up matters. And if you end up encoding deploy state somewhere on the server, now that state matters too.
The flow we were aiming for was basically this:
- name: rebuild passive app
docker_compose_v2:
services:
- app_green
build: always
- name: wait for health
uri:
url: http://app_green:3000/health
- name: switch proxy
template:
src: upstream.conf.j2
dest: /srv/app/upstream.conf
We had a version of this where the proxy logic was more explicit, with the concept of choosing which slot was active and then switching over only after the target app looked healthy. Reasonable approach. But then I realized we were adding a fair amount of operational ceremony to compensate for the fact that we still had a pretty small deployment topology underneath. At some point I started thinking: if we need too much logic just to make this feel safe, maybe we are pushing Docker Compose harder than it wants to go.
That was one of the constraints the whole time. I wanted to keep the code clean and simple. If we were going to build a complicated orchestration layer, then it would have been more reasonable to move to an orchestration system like Kubernetes and stop pretending Compose plus some scripts was the same thing. I did not want a half-Kubernetes hidden in YAML and deploy tasks.
So we tried to change direction a bit.
Second try
Instead of treating green and blue as two completely separate slots where only one is really alive, we tried to make the setup more boring. Same Dockerfile. Same Compose structure. Two app services, app_blue and app_green, defined from the same base configuration. Different image tags, same application, same internal port, same mounted volumes for the persistent bits the app needs. That part is actually quite clean. Compose handles it well enough, and the config stays readable.
Something closer to this:
services:
app_blue: &app
image: app:blue
build: .
expose:
- "3000"
app_green:
<<: *app
image: app:green
Then the question became less "which slot do we promote" and more "how do we update sequentially without dropping traffic." And this is where the single replica limit kept getting in the way.
The first green-blue approach with one replica per side did not work the way we liked. It worked enough to be interesting, but not enough to feel solid. So then we tried to bump the replica count to two so that we could update application one and then application two, sequentially, while keeping capacity online. That felt closer to what we actually wanted from the start.
At that point the deploy flow became more pragmatic. Bring up the infrastructure services. Rebuild one app container. Wait for health checks. Then rebuild the other one. Keep the proxy in front, keep routing stable, and let the healthy instances absorb traffic while the next one is rotating. It is not a pure textbook green-blue rollout anymore. It is more like using the same idea to get rid of the most obvious downtime.
So the deploy logic started looking more like this instead:
- name: ensure infra is up
docker_compose_v2:
state: present
- name: rebuild first app
docker_compose_v2:
services: [app_blue]
build: always
wait: true
- name: rebuild second app
docker_compose_v2:
services: [app_green]
build: always
wait: true
And yes, this is probably where I might be a bit excessive, because part of me still likes the cleaner story of one side being green, one side being blue, and traffic switching in a very explicit way. But in practice, sequential updates with more than one running instance felt less fragile than a dramatic slot swap on top of a tiny fleet.
Proxy and health checks
We also changed the proxy side during this work. The branch evolved from an nginx-based switching idea toward Traefik sitting in front of both application containers. That made some parts easier, because the proxy could discover backends directly and the routing rules stayed more declarative. I liked that. It removed some of the manual moving parts. At the same time, it also made it pretty clear that we were still doing custom orchestration logic, just in a tidier form.
One detail that helped was leaning more on health checks. If the app is not exposing a trustworthy readiness signal, all of this becomes theater very quickly. We used the app health endpoint as the gate before considering a rebuilt container usable. That sounds obvious, but it is the difference between "we started a container" and "we can actually send traffic to it." With green-blue, or with sequential rolling updates on a tiny fleet, that's everything.
Even a tiny example like this changes the quality of the rollout quite a lot:
healthcheck:
test: ["CMD", "curl", "-f", "http://localhost:3000/health"]
interval: 15s
timeout: 30s
retries: 20
Another part I cared about was keeping the Compose file from turning into a mess. We reused the same service definition as much as possible and just specialized what had to be different. Same Dockerfile, same environment, same volumes, same exposed app port. Only the image naming and service identity really changed. That is important because once deployment config starts to fork too much between blue and green, you create another class of bugs where one side behaves differently for accidental reasons.
Limits
Anyway, the result was mixed.
The thing is working. That part is true. We got to a point where the deployment behavior is better than the original single-instance replacement, and the downtime story improved enough to justify the effort. But the complications were a bit too much to call it a real success. Not because any single piece was absurdly hard, but because the whole chain is still more delicate than I would like for something that is supposed to stay simple.
And that is probably the honest conclusion here. If you are deploying a small fleet with Docker Compose and Ansible, green-blue ideas can help, especially if your current flow just tears down the only running app and waits for the new one to come back. There is real value in separating "rebuild this" from "send traffic here." But the quality of the result depends a lot on how much actual redundancy you have. If each side only has one replica, the setup can get awkward fast.
So for me the biggest lesson was about topology: two replicas make sequential updates much more natural. And keeping the deploy logic simple is not just a style preference. It is a way to know when you are reaching the point where maybe Compose is no longer the right level of abstraction.
Takeaway
If I had to leave one takeaway, it would be this: green-blue sounded like the clean answer, but in our case the real improvement came from reducing downtime without letting the deployment logic become too clever. We got part of the way there. Not perfect, but it works well enough to be useful.
The open question for me is still where to draw the line. If we need one more layer of custom behavior to make this feel truly robust, I am not sure I want that layer to live in Ansible and Compose. That is usually the point where I start thinking maybe the simple solution is no longer simple.